Development of a Product Recommendation System Using Web Scraping 10.000+ Data, PySpark, Apache Airflow, and Integration with Llama 3.1
DATA SCIENCEA comprehensive product recommendation system project focused on building similarity-based recommendations using data scraped from padiUMKM platform. The system integrates various technologies including Selenium, BeautifulSoup, PySpark, PostgreSQL, and Llama 3.1 for enhanced contextual recommendations.
Project Highlights
- Scraped over 100,000 product entries using Selenium and BeautifulSoup
- Implemented data transformation and cleaning using PySpark
- Developed similarity-based recommendation system with Cosine Similarity
- Integrated Llama 3.1 for enhanced contextual recommendations
- Built real-time recommendation service with continuous data updates
Technologies Used
Project Stages
Stage 1: Web Scraping
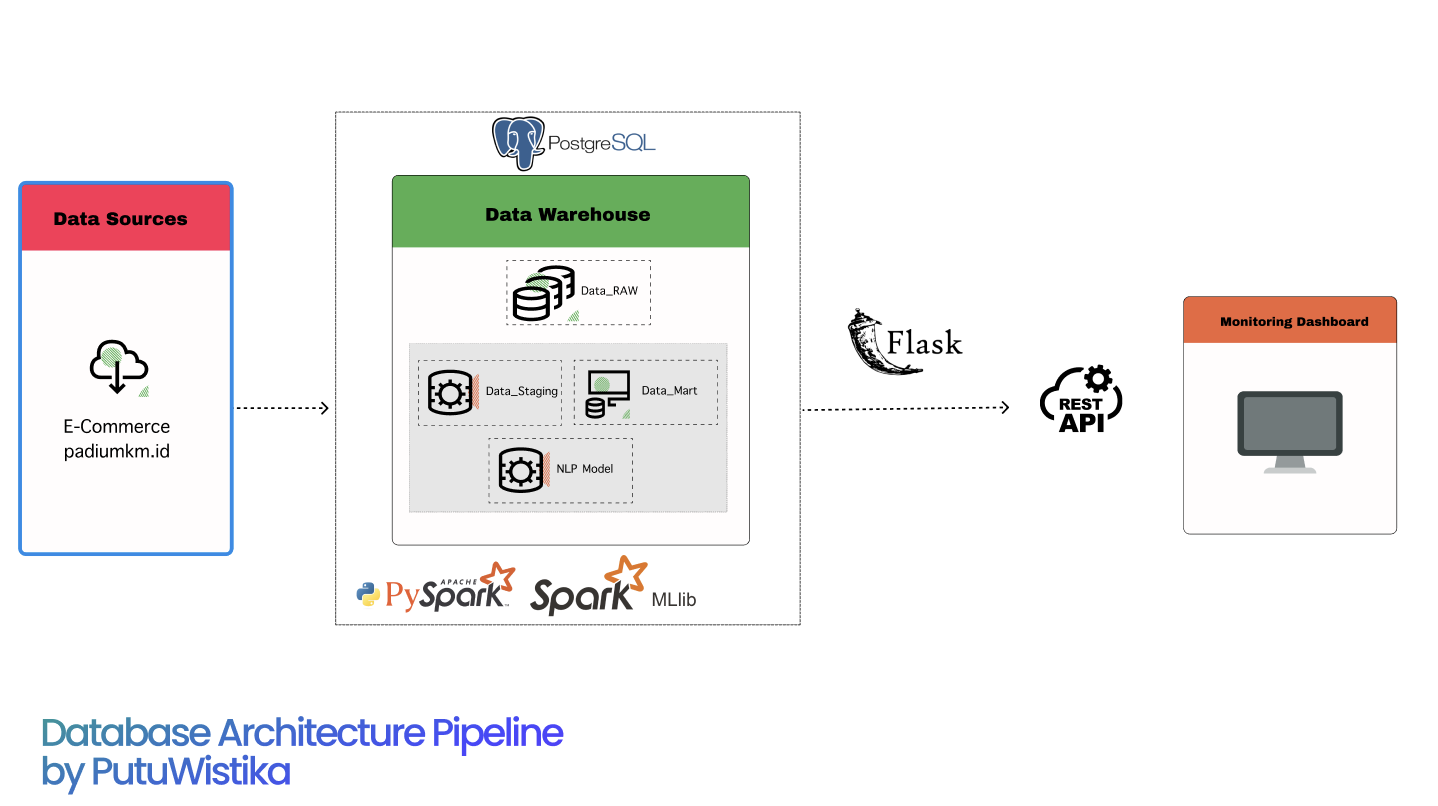
Developed automated scraping system using Selenium and BeautifulSoup to collect product data including names, prices, stock, sales, ratings, descriptions, dimensions, and weights from padiUMKM platform.
Stage 2: Data Processing
Implemented data transformation pipeline using PySpark for consistency checking, normalization, and data cleansing. Established PostgreSQL database connection for data storage.
Stage 3: Recommendation Model
Built similarity-based recommendation system using Cosine Similarity algorithm, utilizing product descriptions and features like categories, brands, and related attributes.
Stage 4: LLM Integration
Integrated Llama 3.1 model through prompt engineering techniques to enhance recommendation quality by understanding linguistic patterns in product descriptions.
Stage 5: Real-time System
Developed real-time data collection and transformation processes, implemented recommendation model as a real-time service for immediate product suggestions.
Stage 6: Testing & Optimization
Conducted comprehensive testing of the recommendation system, optimized model performance, and validated recommendation accuracy.